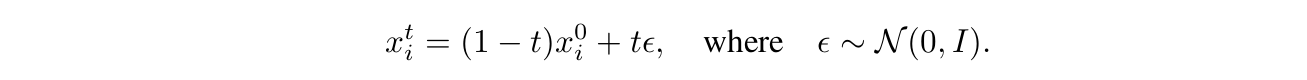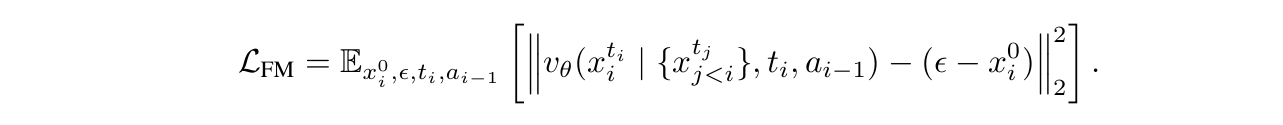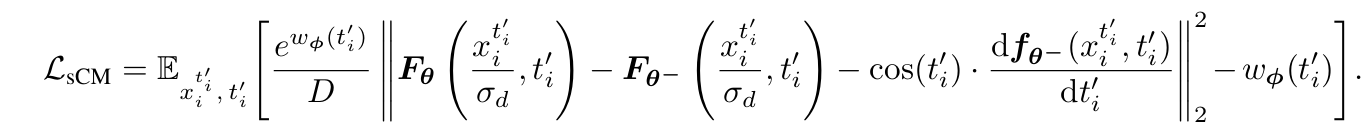Autoregressive video models offer distinct advantages over bidirectional diffusion
models in creating interactive video content and supporting streaming applications
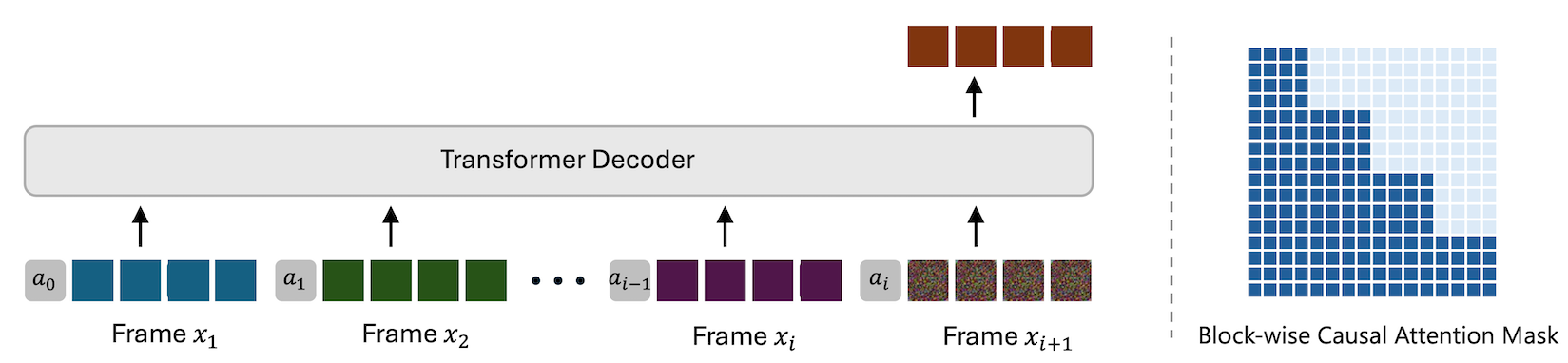
with arbitrary duration. In this work, we present Next-Frame Diffusion (NFD), an
autoregressive diffusion transformer that incorporates block-wise causal attention,
enabling iterative sampling and efficient inference via parallel token generation
within each frame. Nonetheless, achieving real-time video generation remains a
significant challenge for such models, primarily due to the high computational
cost associated with diffusion sampling and the hardware inefficiencies inherent
to autoregressive generation.
To address this, we introduce two innovations:
(1) We extend consistency distillation to the video domain and adapt it specifically for
video models, enabling efficient inference with few sampling steps;
(2) To fully leverage parallel computation, motivated by the observation that adjacent frames
often share the identical action input, we propose speculative sampling. In this
approach, the model generates next few frames using current action input, and
discard speculatively generated frames if the input action differs. Experiments
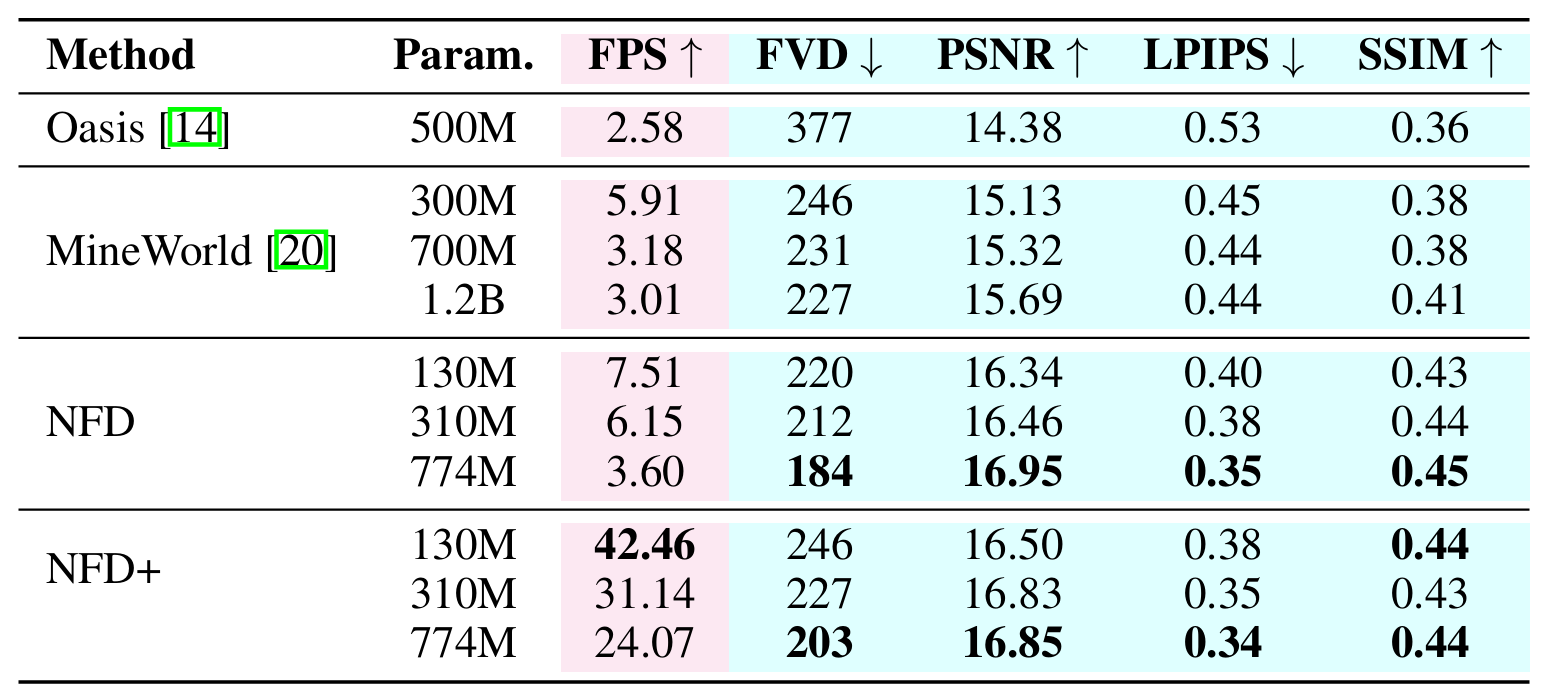
on a large-scale action-conditioned video generation benchmark demonstrate that
NFD beats autoregressive baselines in terms of both visual quality and sampling
efficiency. We, for the first time, achieves autoregressive video generation at over
30 Frames Per Second (FPS) on an A100 GPU using a 310M model.